
研究テーマ
機械学習 Machine Learning
ラベルが誤った教師データを用いた深層学習
ディープニューラルネットワーク(DNN)が高い性能を発揮するためには、大量の正確なラベル付きデータが必要です。しかし、現実的には、正確なラベル付けが困難で、ノイズのあるラベル(ノイジーラベル)が含まれることがあります。DNNをノイジーラベルを含むデータで学習させると、性能が大幅に低下します。そこで、本研究では、ノイジーラベルを含むデータを用いてもDNNの高い性能が発揮できる学習アルゴリズムの開発に取り組んでいます。
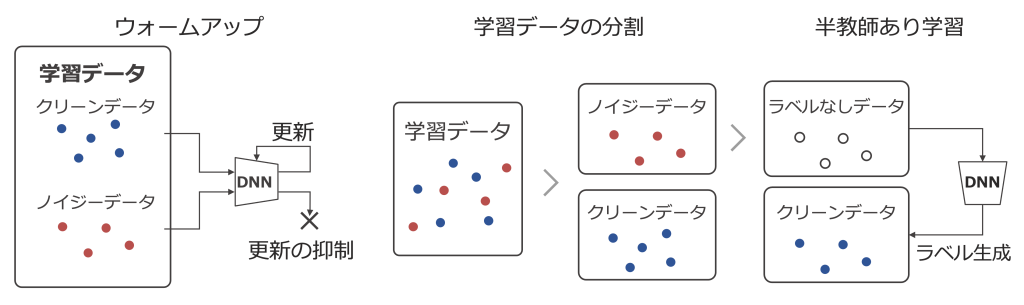
現在の主流な学習アルゴリズムは、ウォームアップ、学習データの分割、半教師あり学習の3段階に分かれています。ウォームアップ段階では、ノイジーデータ(ノイジーラベルを持つデータ)のネットワークパラメータの更新を抑制し、クリーンデータ(正確なラベルを持つデータ)のみで学習が進められます。これにより、学習データの分割段階でノイズの多いデータを効果的に除去することができます。最後に、半教師あり学習段階では、ノイジーデータのラベルを破棄し、DNNの出力から新しいラベルを生成して付与することで、分割後の少量のクリーンデータだけを使った場合よりも高い性能を実現します。このアプローチにより、DNNはノイジーラベルを含むデータでも効果的に学習することが可能になります。
- 東本 良太,吉田 壮,棟安 実治:学習初期の正則化と加重損失を用いたラベルノイズに頑健な半教師あり学習,SIS2022-16,pp.27-32 (2022年10月)
- H. Takeda, S. Yoshida,and M. Muneyasu: Training Robust Deep Neural Networks on Noisy Labels Using Adaptive Sample Selection with Disagreement, IEEE Access, vol. 9, pp. 141131-141143, Oct. 13, 2021 DOI: 10.1109/ACCESS.2021.3119582
ドメイン適応
DNNは、画像分類タスクにおいて高い性能を発揮しています。DNNの問題点として、学習に用いた画像と異なるドメインの画像をうまく分類できないことが挙げられます(例:手書きの絵を用いて学習し、実写の画像を分類する)。この問題を解消するため、ドメイン適応(Domain Adaptation)と呼ばれる手法が盛んに研究されています。我々はこの中でも特に、地理的なドメインの変化(例:ヨーロッパ→アジア)に注目しています。
画像に地理的なドメインの変化が生じると、背景の特徴が大きく変化することがあります。その結果、DNNは背景の特徴と分類クラスの間に生じる誤った相関を学習してしまい、分類精度が低下します。本研究では、この問題を解消することで、地理的なドメインの変化に頑健なDNNの実現を目指しています。

動的なグラフ構造の解析と予測
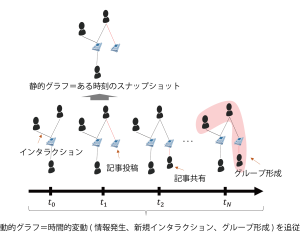
テンポラルグラフラーニング(TGL)は、時間変化するグラフ構造を解析するためのアプローチです。この研究分野は、グラフ理論と機械学習を融合させ、時間に沿って進化する複雑なネットワークの挙動を理解し、予測することを目指しています。
TGLは特に、ソーシャルメディアネットワークなど、時間と共に変化するネットワークデータに有用です。この技術は、ノード間の関係性の変化を捉え、これらの変化が全体のネットワーク構造に及ぼす影響を分析します。
当研究室では、TGLのための新しいアルゴリズムとモデルを開発しています。これらは、ネットワークの時間的ダイナミクスを捉えるために、深層学習技術とグラフ理論の両方を組み合わせたものです。私たちの目標は、より正確で効率的な方法で動的ネットワークを解析し、将来のトレンドやパターンを予測することです。この研究は、ソーシャルメディアのトレンド分析、ニュースの拡散予測など、様々な応用が期待されています。
中国漢代木簡の文字検出・字体分析
近年の文字検出器は、DNNを用いてモデル化され、自然なシーンのテキスト検出や歴史的文書の文字検出など、さまざまなタスクで高い性能を達成しています。しかし、既存の方法では、木簡の多様な文字サイズや縦横比、高密度な文字配置、文字間の距離が近いことなどから、木簡に対する高精度な検出ができません。我々は、文字領域と文字間の境界を学習するU-Netベースの文字検出・位置特定フレームワークを提案しました。
提案された方法は、文字間の垂直および水平の境界を同時に学習することで、文字領域の学習性能を向上させます。さらに、学習された文字境界領域を用いたシンプルで低コストの後処理を追加することで、近接する文字群の位置をより正確に検出することが可能になります。本研究では、独自に木簡データセットを構築しています。実験の結果、提案された方法は、歴史的文書の最先端の文字検出方法を含む既存の文字検出方法よりも優れた性能を示しました。

中国書道の書きぶりの印象評価
書道、特に中国書道は、その深い歴史と独特な技法により、世界中の多くの人々に親しまれています。書き手の感情や技巧が紙に表れる「書きぶり」は、その美しさや力強さを感じ取るための重要な要素となっており、人々が書道作品に感動する背景には、この「書きぶり」への印象評価が深く関わっています。
しかしこの書きぶりの印象評価を、客観的に、そして大量の作品に対して効率的に行うことは容易ではありません。ここで、人工知能の力を借りることで、この問題に新たなアプローチを試みることが当研究の動機となります。
当研究室では、伝統的な書道のルールに基づいた特徴や、人々の印象に関連する要因を取り入れた新しい評価手法を開発しています。具体的には、手書き画像を含むデータベースを用いて、ニューラルネットワークによる書きぶりの印象評価の可能性を探求しています。